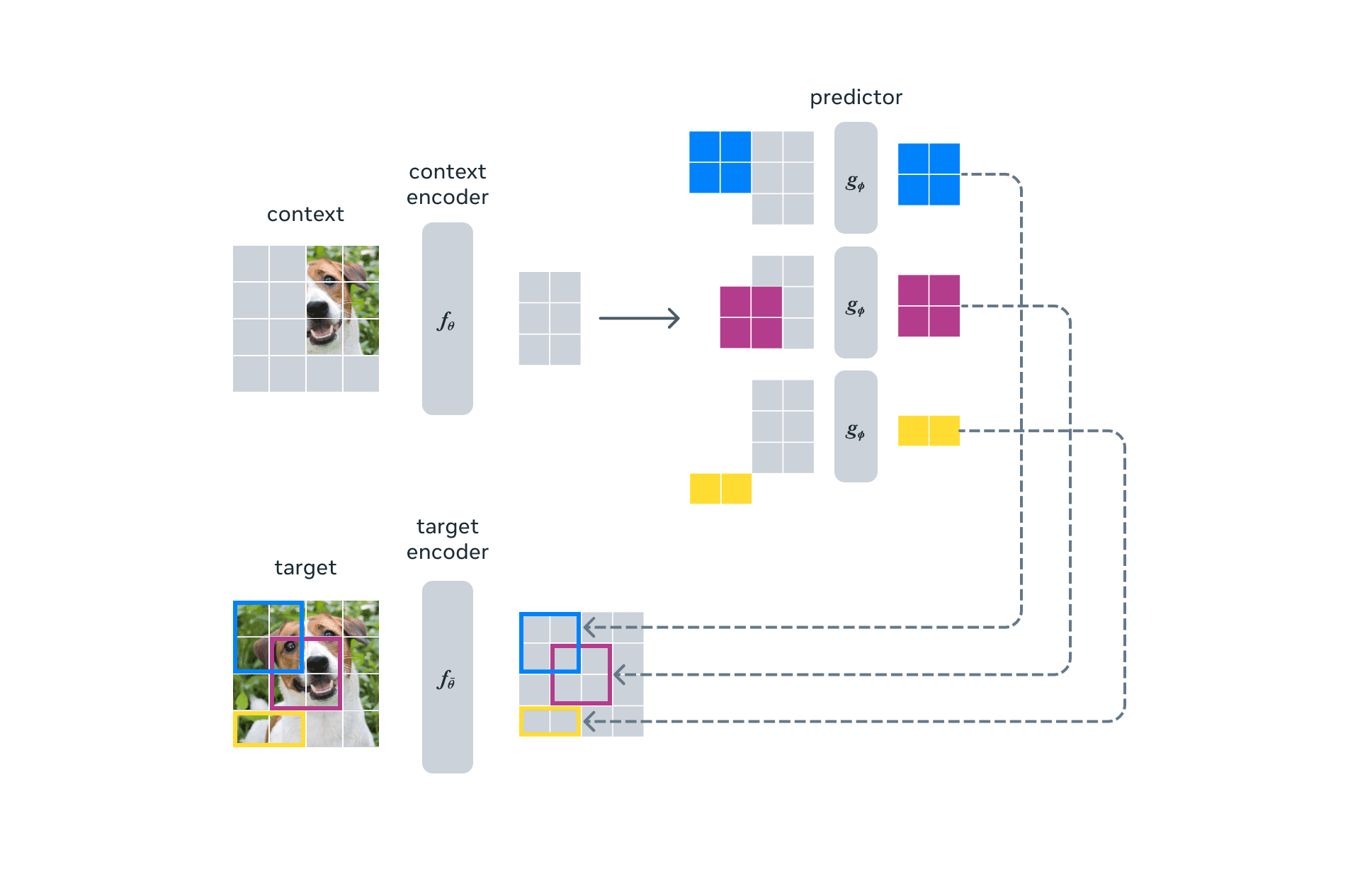
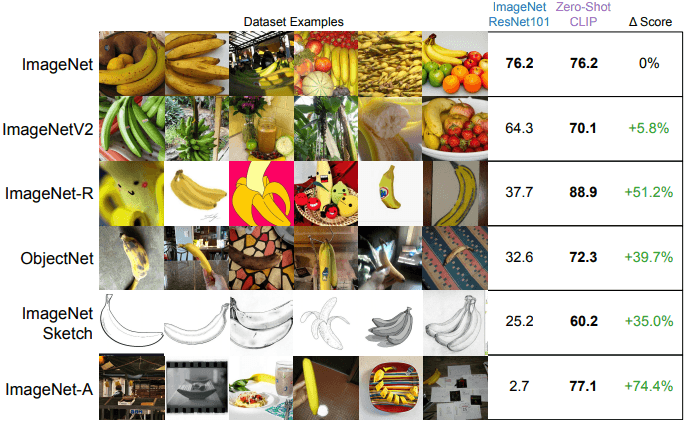
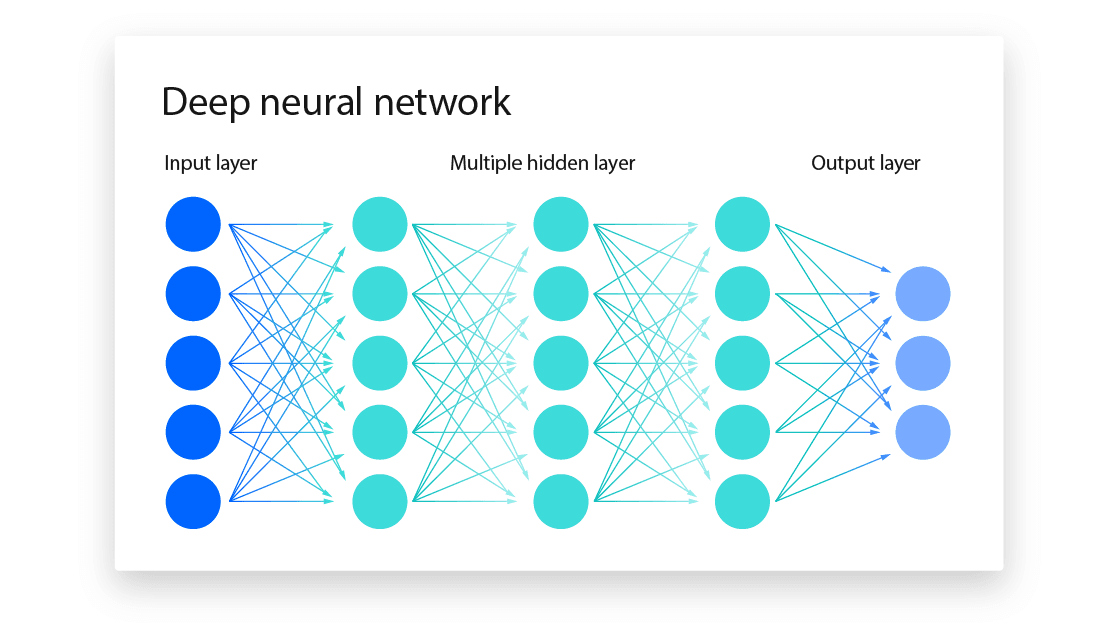
What is CLIP and why does it matter?Paper: Learning Transferable Visual Models From Natural Language Supervision, Radford et al. (2021) Introduction As we discussed in previous posts, Contrastive Learning isn't new. For example, FAIR's Moco was published in 2019, along with many other ...May 12, 2025·3 min read
Branch Misprediction in HumansBranch prediction refers to a CPU's ability to predict the outcome of a boolean statement to streamline processing. This concept parallels human decision-making, where people continuously assess potential outcomes based on experience and inference, o...Apr 15, 2025·2 min read
Should we ship this feature?Introduction During my time at tech companies, one of the most challenging tasks for my team has been guiding the Product team in their decision to launch a feature. This process is both highly consequential and fraught with potential pitfalls. Let's...Aug 1, 2021·4 min read
My new role at Lyft (2018)In October, I joined Lyft as Data Science Manager for Core Mapping. I wish I could have posted this update a while ago but a big event got in the way (yes, we went public) ... While low visibility, Mapping turns out to a big deal for ride-sharing as ...Oct 1, 2018·3 min read