Should you ship this feature?
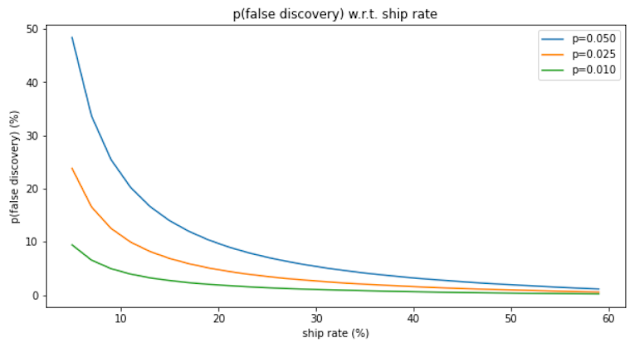
Introduction During my time at tech companies, one of the hardest tasks for my team is to guide the Product team in their decision to launch a feature. It is both very consequential and also very fraught with pitfalls. Let's take an example to ease into the topic: You worked hard to convince leadership to measure the effect of this cool new feature and you got a nice experiment set up according to the cannons of measurement. After 4 weeks, you are seeing stat sig improvement in your primary metric and not secondary metrics affected negatively. The story is clear as day: you should tell the team to ship it, right? The problem with shipping features Once the results are out, the focus is put on the outcomes and leadership is incentivized to ship. As a result, little attention is given to cost side of the equation: Tech debt : Does this feature make the system more complex? Does it hinder long term growth by exacting a tax from any new feature? Think about Net Prevent Value of such t





